Complete SQL Subqueries Tutorial
SQL subqueries are a common element in SQL queries. They allow
for performing complex queries and dynamic filtering and
calculations based on the results of other queries, enabling
more efficient and targeted data retrieval from the database.
Nonetheless, like any technique, it is critical to know how to
apply it correctly. This material will explore SQL subqueries
— their classifications, scope, and the most effective SQL
strategies.
Understand SQL subqueries
In SQL, a subquery refers to a query nested within another
query, such as a
SELECT,
UPDATE,
INSERT, or
DELETE
statement. This subquery functions as a condition in the primary
query, supplying it with a selected data subset based on
specific criteria. In essence, subqueries break down a
sophisticated, sizeable query into distinct logical components
executed sequentially. This approach is beneficial as it
enhances the readability and maintainability of the code.
Typically, subqueries are not confined to a single strict syntax
scheme — they encompass diverse parameters. For the SELECT
statement, which is the most common usage scenario, the syntax
typically appears as follows:
SELECT
column_name
FROM table_name
WHERE column_name
OPERATOR
(SELECT column_name [, column_name]
FROM table1 [, table2]
[WHERE]);
Note that the subquery needs to be enclosed in parentheses.
Additionally, ensure that you specify only one column in the
SELECT clause. If you wish to apply optional parameters to sort
the results, be mindful not to use ORDER BY within the subquery,
as it is only permissible in the main query. Instead, the
subquery can employ GROUP BY for achieving the same sorting
objective as ORDER BY.
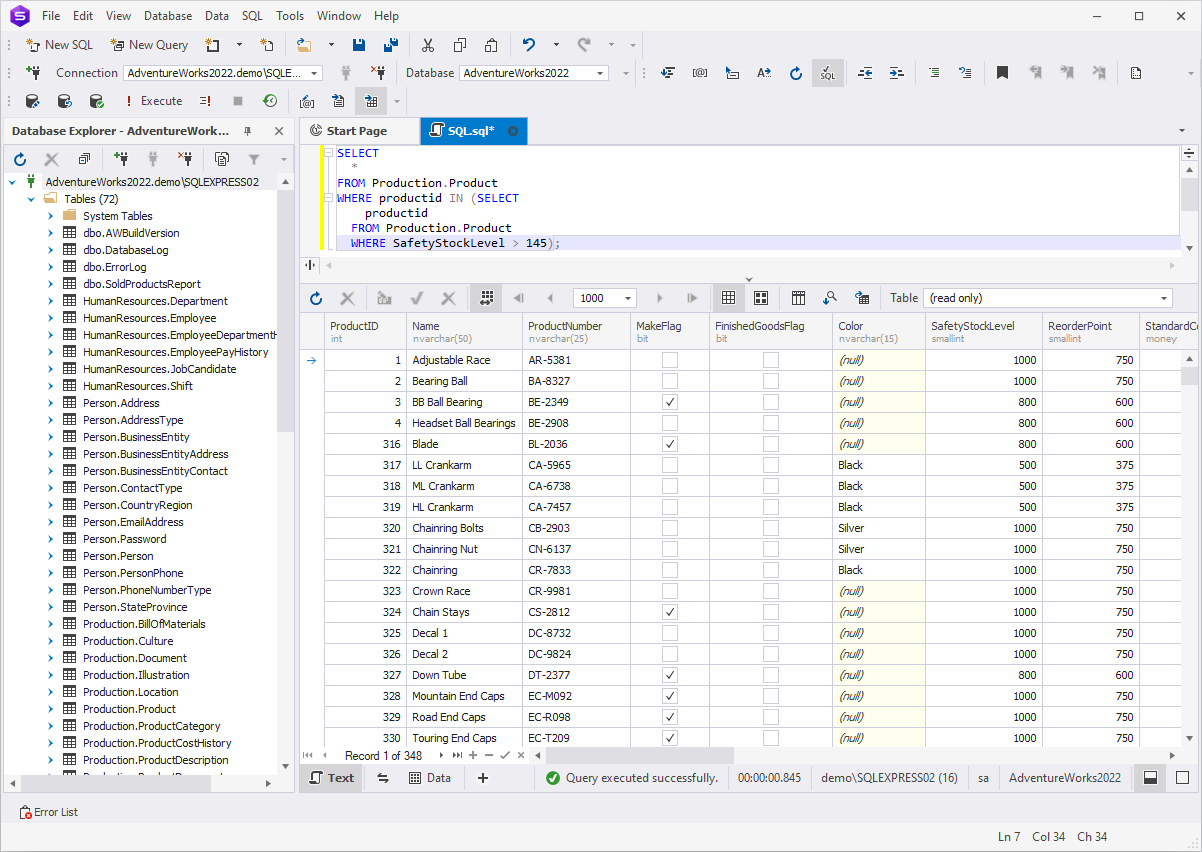
Consider the following example that examines all products
available in stock with a quantity exceeding 145 items (the test
database AdventureWorks2022 is used).
SELECT
*
FROM Production.Product
WHERE productid IN (SELECT
productid
FROM Production.Product
WHERE SafetyStockLevel > 145);
Subqueries are frequently utilized in conjunction with the
IN (or NOT IN) operators within the WHERE clauses. The WHERE
clause enables SQL specialists to accurately filter the results
and obtain more precise output from the main query. By applying
the WHERE condition, the system can compare the column in the
main table with the results of the subquery.
The IN operator enables us to specify multiple values in the
WHERE clause and determine how the expression matches the output
value(s). The use of IN/NOT IN operators eliminates the
necessity for multiple OR conditions in the query.
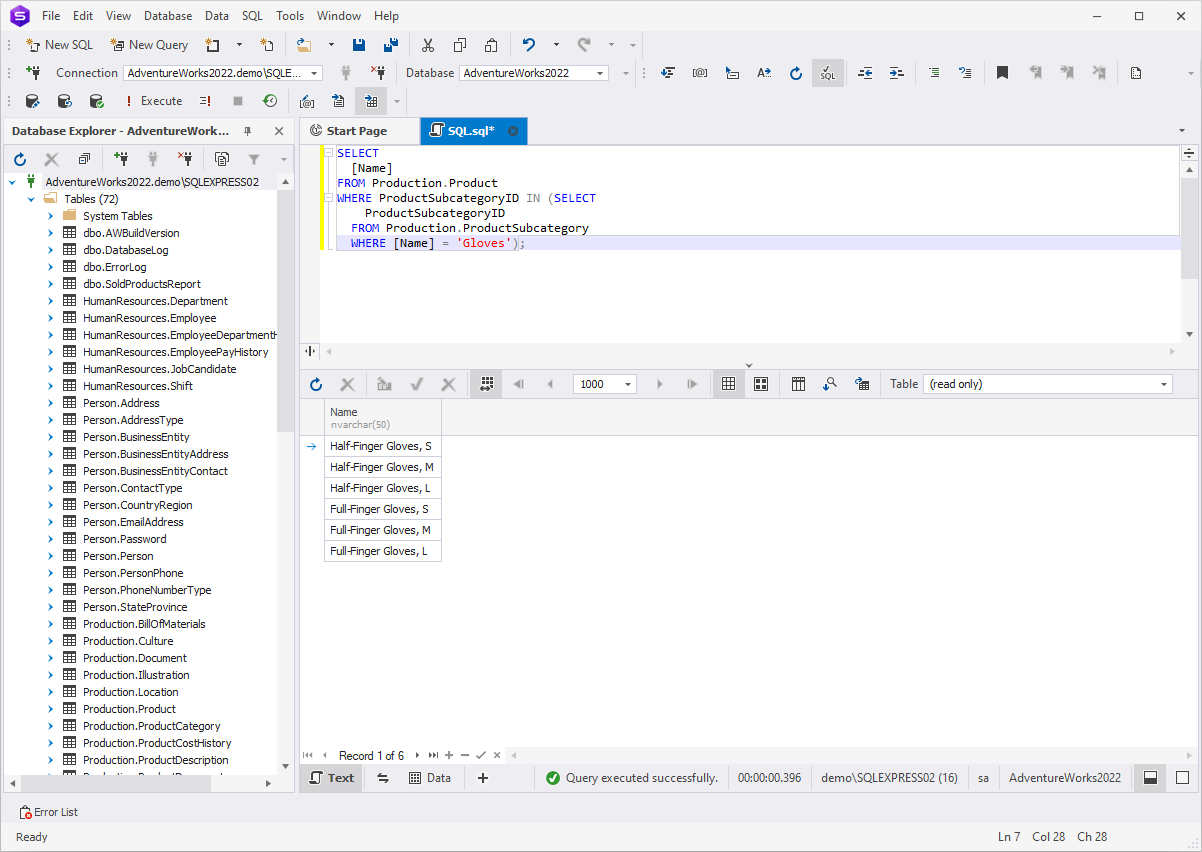
SELECT
[Name]
FROM Production.Product
WHERE ProductSubcategoryID IN (SELECT
ProductSubcategoryID
FROM Production.ProductSubcategory
WHERE [Name] = 'Gloves');
In the above example, the subquery outputs the ID of the
subcategory matching the name 'Gloves' and then passes it to the
main query that finds the product names matching the
subcategory's ID. The output is the list of all 'gloves' items
available in the database.
Types of SQL subqueries
Subqueries are categorized into three groups based on their
syntax specificity and query purpose:
- Scalar subqueries
- Multi-row subqueries
- Correlated subqueries
Let us explore them all.
Scalar subqueries
A scalar subquery is a type of subquery that returns a single
value, either one column or one row. It is the simplest subquery
format used in the SELECT statement, typically combined with the
WHERE, HAVING, or FROM clause, along with a comparison operator.
The most common use case for a scalar subquery is to reference
an aggregate value such as average, maximum, minimum, sum, or
count. The subquery retrieves the value, which is then used by
the main query. If the subquery returns zero rows, it implies
that the value returned by the subquery expression is NULL.
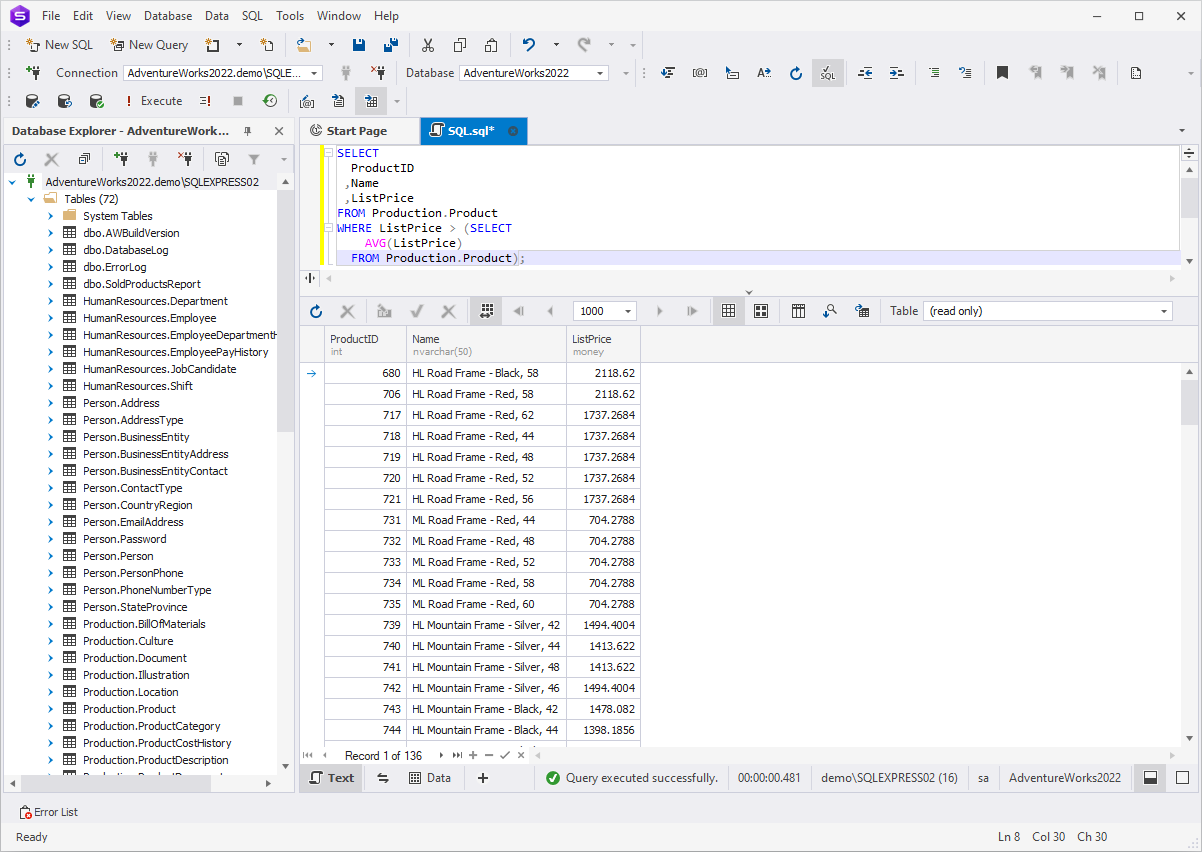
Let's consider an example where we want to identify products
with prices higher than the average product price. We use the
below query with a subquery:
SELECT
ProductID
,Name
,ListPrice
FROM Production.Product
WHERE ListPrice > (SELECT
AVG(ListPrice)
FROM Production.Product);
The subquery in parenthesis — (SELECT AVG(ListPrice) FROM
Production.Product) — is the scalar subquery. It
calculates the average price across all products and returns
that average value. The main query uses his value to compare the
list prices of all products. The result of the entire query is
the list of products with prices greater than average.
Multi-row subqueries
A multiple-row subquery is a form of subquery that can return
one or several rows for the main SQL query to utilize in its
operations. Much like scalar subqueries, these can be
incorporated within the SELECT statement, and used in
conjunction with the HAVING, WHERE, and FROM clauses. However,
they are applied together with logical operators such as ALL,
IN, NOT IN, and ANY.
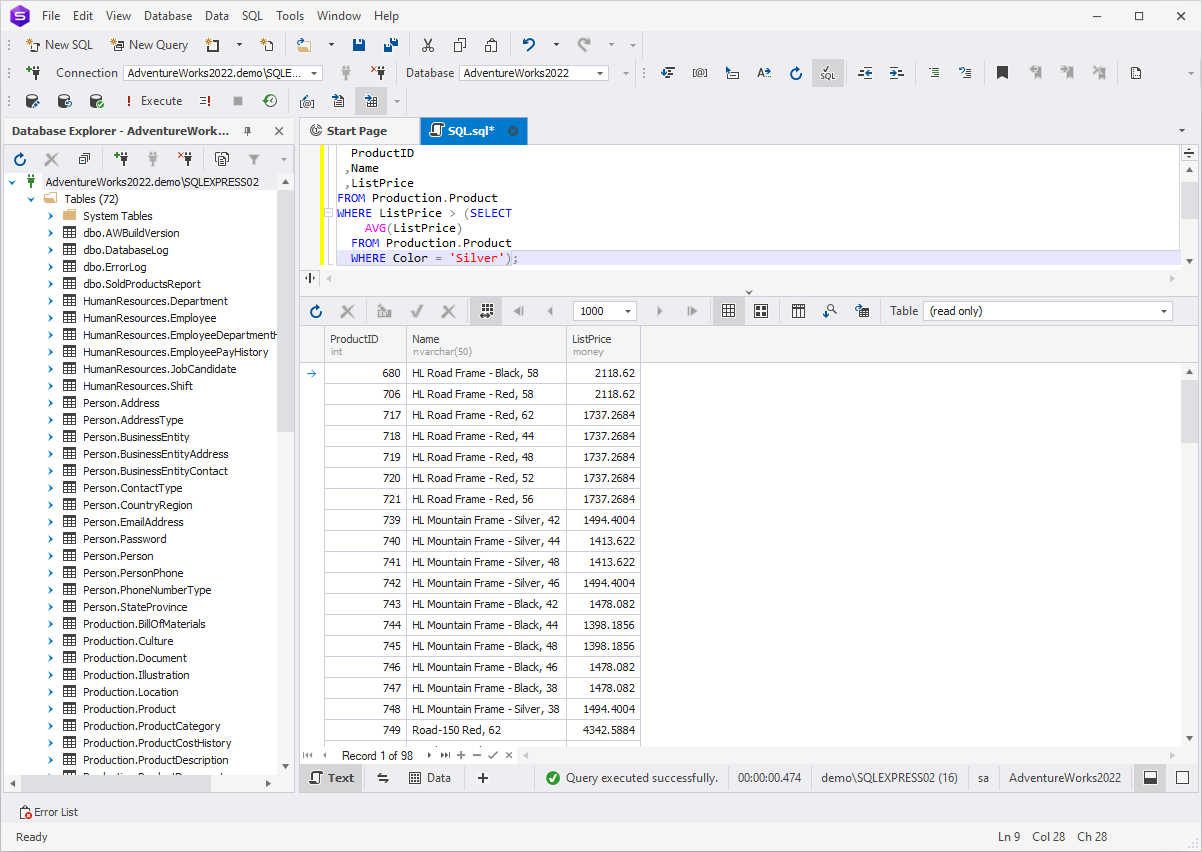
The example provided below is a more nuanced version of a
previous example. Once again, we are aiming to list the products
priced higher than average. However, this time the average is
not calculated across all products in the database. Instead, it
specifically pertains to products within a designated category.
SELECT
ProductID
,Name
,ListPrice
FROM Production.Product
WHERE ListPrice > (SELECT
AVG(ListPrice)
FROM Production.Product
WHERE Color = 'Silver');
This query retrieves the data specifically associated with
unique products, applies a filter to focus only on products with
the color "silver," and calculates the average price for that
category. The main query displays the list of products that have a
price higher than the average price of products in the "silver"
color category.
Correlated subqueries
A correlated subquery is a specific type of subquery that
produces multiple columns, but the output depends on the
requirements defined by the main query. In this type of query,
the main query and the subquery rely on each other. As a result,
the query cannot be executed in separate, sequential steps.
Instead, a correlated subquery operates repeatedly for each row
in the output. For this reason, correlated subqueries are also
known as repeated subqueries.
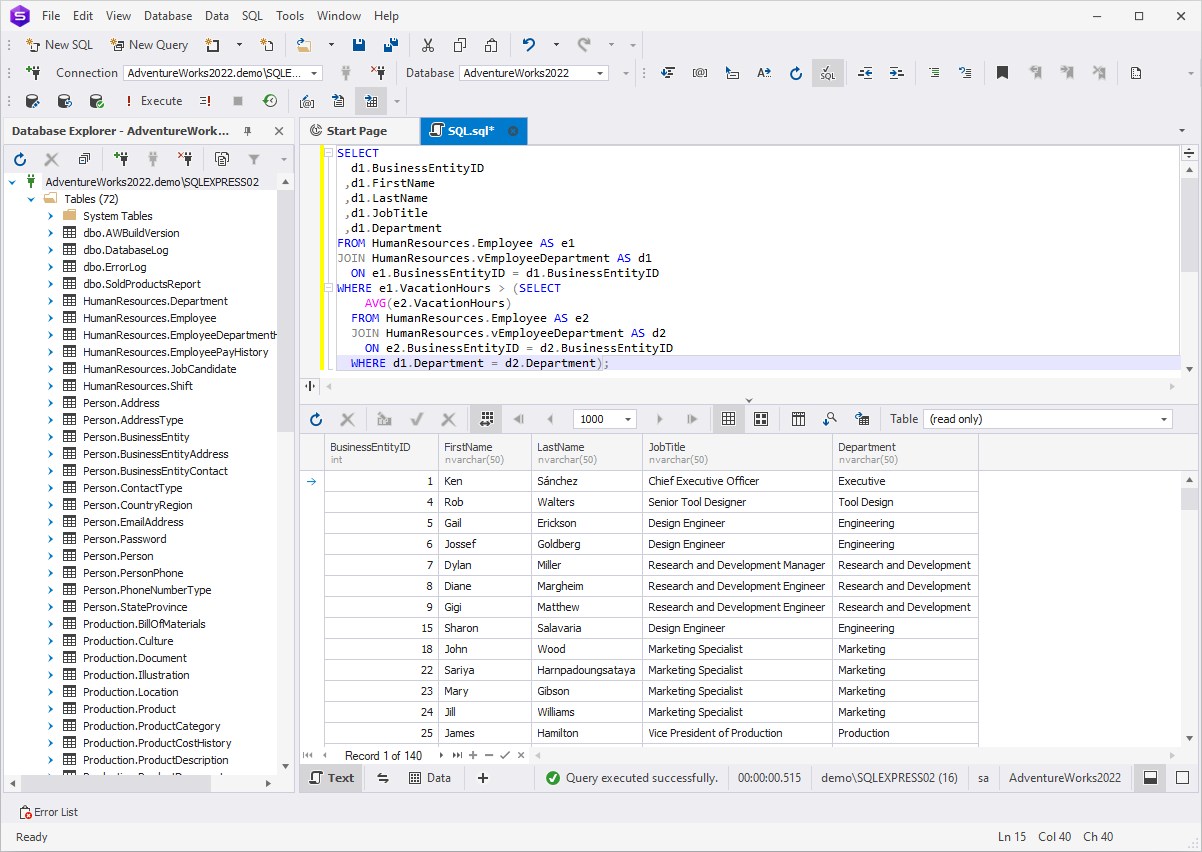
The below query selects the information above the employees who
have more vacation hours than average in their respective
departments.
SELECT
d1.BusinessEntityID
,d1.FirstName
,d1.LastName
,d1.JobTitle
,d1.Department
FROM HumanResources.Employee AS e1
JOIN HumanResources.vEmployeeDepartment AS d1
ON e1.BusinessEntityID = d1.BusinessEntityID
WHERE e1.VacationHours > (SELECT
AVG(e2.VacationHours)
FROM HumanResources.Employee AS e2
JOIN HumanResources.vEmployeeDepartment AS d2
ON e2.BusinessEntityID = d2.BusinessEntityID
WHERE d1.Department = d2.Department);
Because of that repeated performance, correlated queries
are quite resource consuming.
How to use SQL subqueries with INSERT, UPDATE, and DELETE
In the previous section of this article, we discussed the common
usage of SQL subqueries in SELECT statements, which is
frequently seen in SQL Server. However, subqueries can be
efficiently utilized in various statements, including important
commands like UPDATE, INSERT, and DELETE. Let's now examine
these specific cases.
Use subqueries in INSERT statements
In the INSERT statement, SQL subqueries allow us to insert the
result set obtained from the subquery into a target table. To
ensure correct execution, it is important to follow certain
rules:
-
Explicitly specify the names of the columns in the target
table where the records will be inserted.
-
Arrange the columns in the SELECT list in the same order as
they appear in the source table.
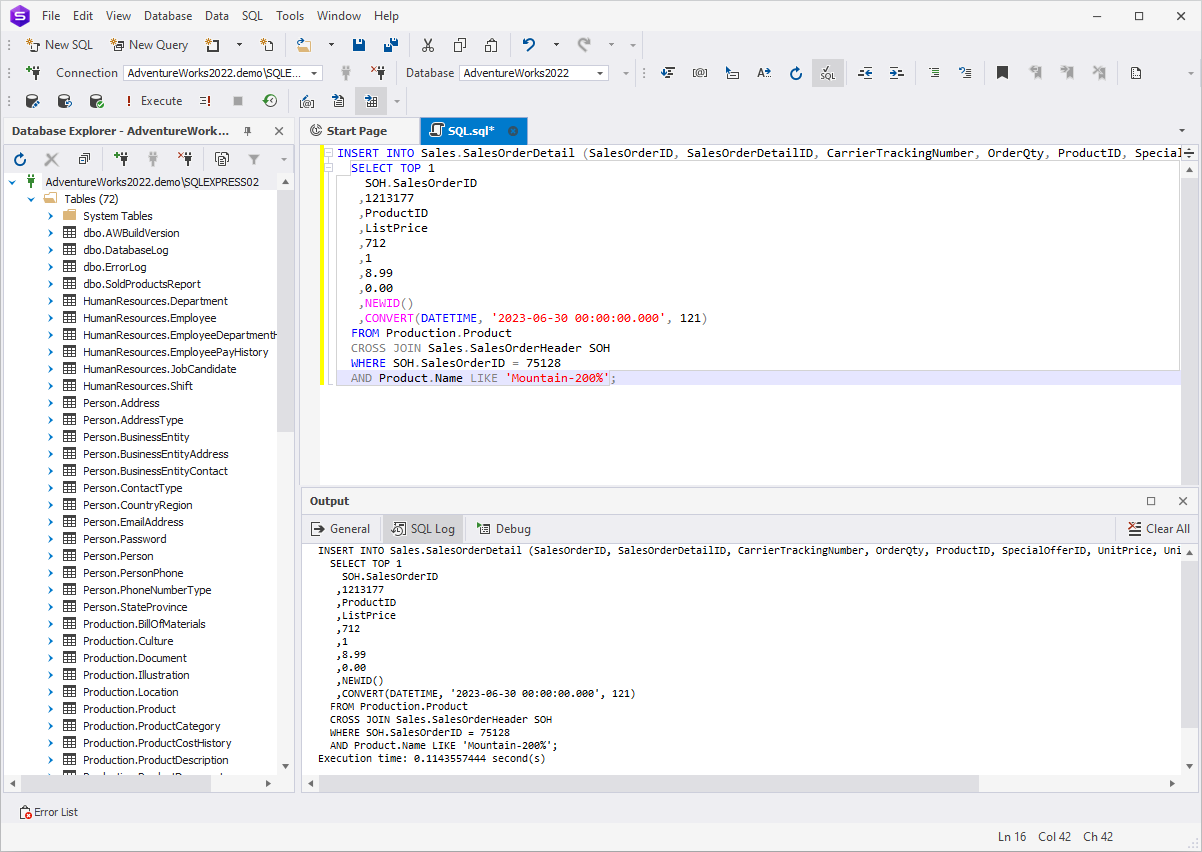
Consider the below example where the SQL query inserts the data
into the SalesOrderDetail table. It selects the data from
the Production.Product and
Sales.SalesOrderHeader tables and uses that data portion
for the INSERT operation.
INSERT INTO Sales.SalesOrderDetail (SalesOrderID, SalesOrderDetailID, CarrierTrackingNumber, OrderQty, ProductID, SpecialOfferID, UnitPrice, UnitPriceDiscount, rowguid, ModifiedDate)
SELECT TOP 1
SOH.SalesOrderID
,1213177
,ProductID
,ListPrice
,712
,1
,8.99
,0.00
,NEWID()
,CONVERT(DATETIME, '2023-06-30 00:00:00.000', 121)
FROM Production.Product
CROSS JOIN Sales.SalesOrderHeader SOH
WHERE SOH.SalesOrderID = 75128
AND Product.Name LIKE 'Mountain-200%';
Use subqueries in UPDATE statements
Subqueries are commonly used in UPDATE statements, particularly
in conjunction with the SET operator. However, subqueries can be
utilized in the WHERE clause too. The SET operator enables us to
assign a new value to the column being modified by the UPDATE
statement. A subquery can be used to derive this new value.
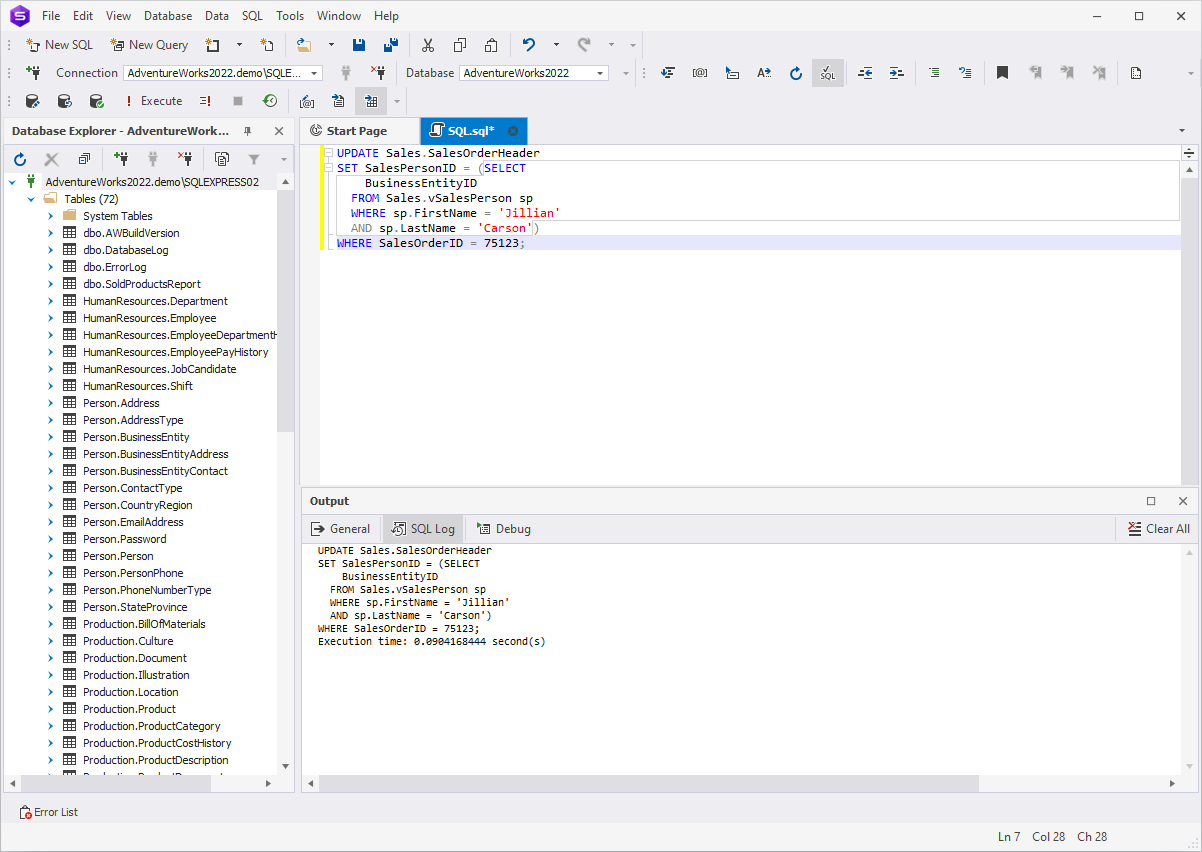
The following example illustrates updating the
SalesPersonID in the SalesOrderHeader table.
UPDATE Sales.SalesOrderHeader
SET SalesPersonID = (SELECT
BusinessEntityID
FROM Sales.vSalesPerson sp
WHERE sp.FirstName = 'Jillian'
AND sp.LastName = 'Carson')
WHERE SalesOrderID = 75123;
Use subqueries in DELETE statements
Subqueries can only be used in DELETE statements with the WHERE
clause. Our objective is to eliminate unpopular products from
stock, specifically those that have had no sales in the past 6
months.
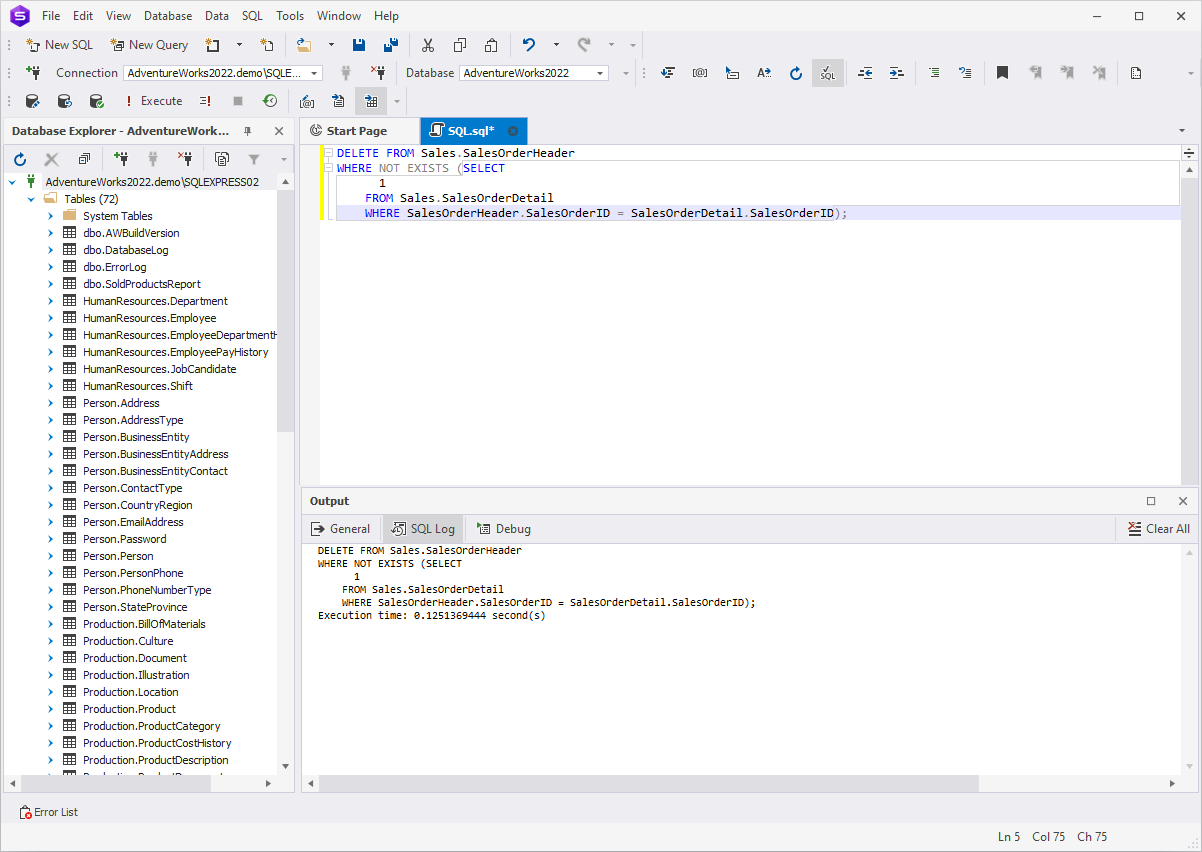
Our objective is to delete some data from the
SalesOrderHeader table. In our scenario, we are removing
those orders that don't have correlated items in the
SalesOrderDetail table.
DELETE FROM Sales.SalesOrderHeader
WHERE NOT EXISTS (SELECT
1
FROM Sales.SalesOrderDetail
WHERE SalesOrderHeader.SalesOrderID = SalesOrderDetail.SalesOrderID);
When using the INSERT, UPDATE, and DELETE commands, it is
important to be cautious as these actions permanently modify the
table contents. Before executing the command, it is crucial to
review the records that will be affected using the SELECT
statement. Additionally, it is highly recommended to create a
backup of the database before making any changes to the tables.
Nesting subqueries
In addition to being included within a clause of a SELECT,
INSERT, UPDATE, or DELETE statement, a subquery can also be
nested within another subquery. This allows a more systematic
execution of intricate queries by breaking them down into
manageable steps. Moreover, the use of nested subqueries can
enhance the readability of the code, as a well-constructed
nested subquery is often easier to comprehend.
It is important to note that a query with subqueries can
potentially have up to 32 levels of nesting. However, the actual
number of levels supported depends on the available machine
resources and the complexity of other expressions involved. In
practice, certain queries may not support such a high level of
nesting due to memory limitations.
Have a look at the below example with several nesting levels:
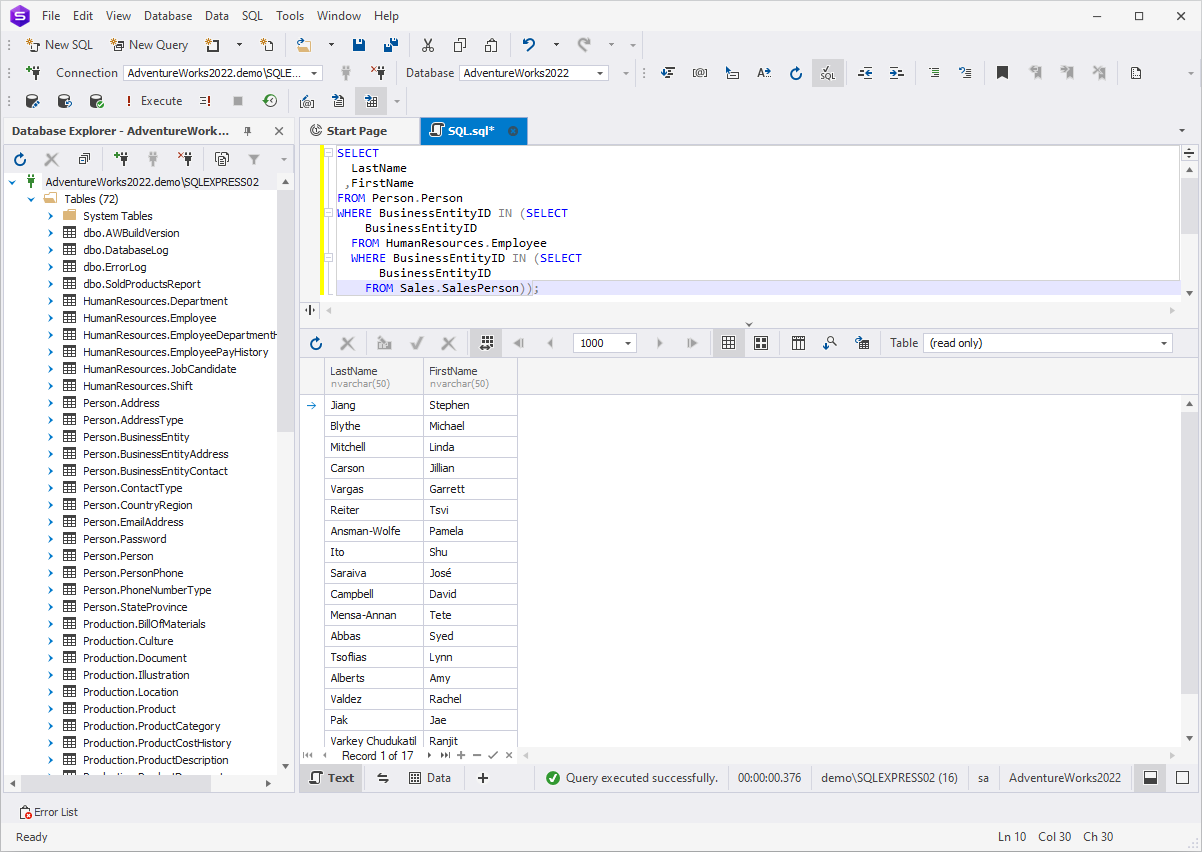
SELECT
LastName
,FirstName
FROM Person.Person
WHERE BusinessEntityID IN (SELECT
BusinessEntityID
FROM HumanResources.Employee
WHERE BusinessEntityID IN (SELECT
BusinessEntityID
FROM Sales.SalesPerson));
The lowest-level subquery retrieves the salesperson's ID. The
higher-level subquery utilizes that value to obtain the contact
ID of the employee associated with that salesperson. The main
query then retrieves the names of the employees that match those
contact IDs.
Nested subqueries can be advantageous and powerful, but
they often involve increased complexity and resource
consumption, particularly when dealing with large databases and
data sets. The choice between using a nested multi-level
subquery or exploring alternative options will depend on the
specific use case, taking into consideration requirements,
restrictions, and available resources.
Use subqueries with the EXISTS keyword
The EXISTS operator is a logical tool used in SQL to verify
whether any rows are returned from a subquery. Rather than
producing data, it simply provides the TRUE response if the
subquery returns a minimum of one row, or a FALSE response if
the subquery returns no rows.
The syntax of the subquery with EXISTS is as follows:
WHERE [NOT] EXISTS (subquery)
Note that the syntax does not include any column names or other
expressions before the EXISTS keyword. Additionally, the
subquery that follows the EXISTS keyword always uses an asterisk
(*) instead of a column list because it only checks for the
existence of rows that meet the specified requirements.
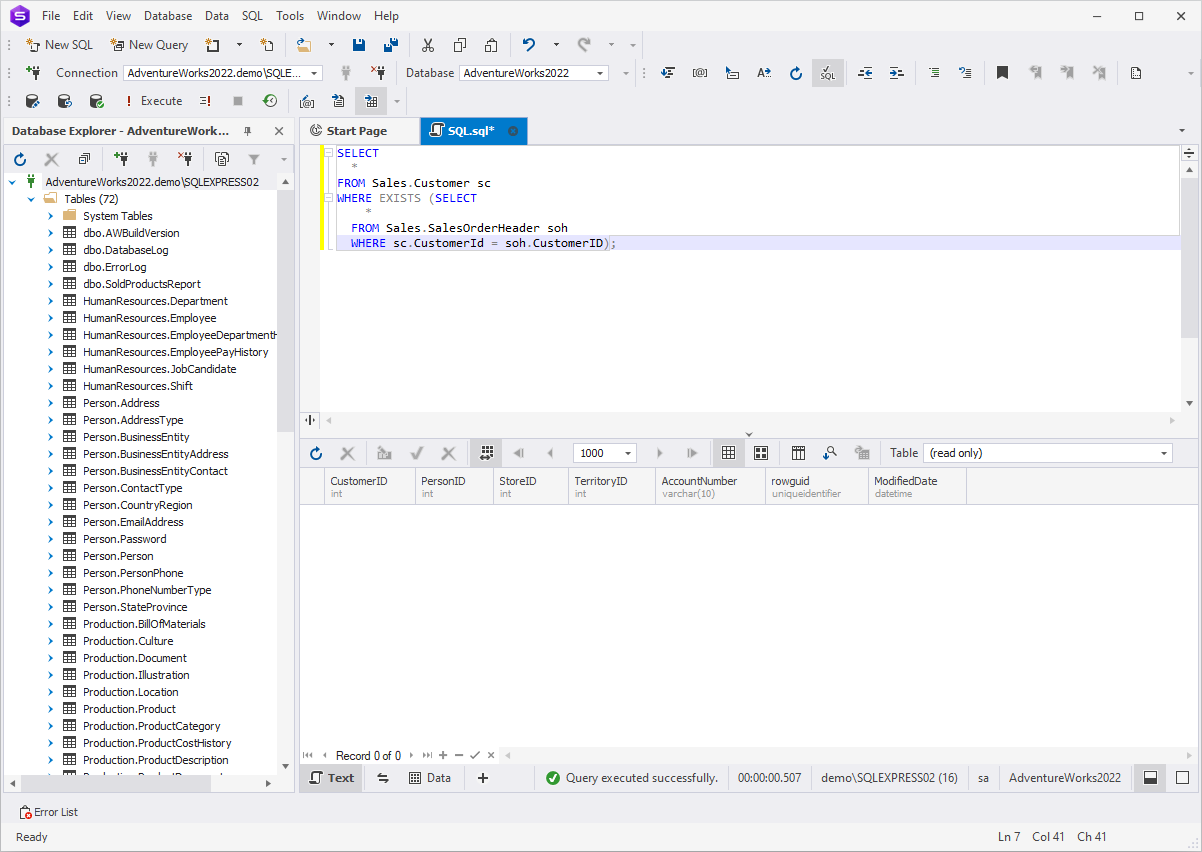
The below example query finds all customers who placed at least
one order:
SELECT
*
FROM Sales.Customer sc
WHERE EXISTS (SELECT
*
FROM Sales.SalesOrderHeader soh
WHERE sc.CustomerId = soh.CustomerID);
While using the EXISTS keyword can be helpful, it is
important to note that SQL queries with this condition are often
inefficient because the sub-query is repeated for every row
involved in the main query.
Performance considerations: subqueries vs JOINs
In SQL Server, there are two options available for retrieving
and combining data from multiple tables: subqueries and
JOINs. In previous sections, we extensively covered subqueries and
demonstrated their functionality in different scenarios. Now,
let's revisit SQL JOINs.
An SQL JOIN is a specific query type that fetches and combines
data portions from multiple tables based on a common condition,
which is usually a common column. The output is a new table
containing the combined and processed data from several database
tables.
When deciding between subqueries and JOINs, the following
aspects should be considered:
Speed
In general, JOINs tend to be faster than subqueries because they
can leverage table indexes and other techniques to improve
performance. However, it's essential to note that subqueries are
not always inferior to JOINs. The performance depends on the
specific conditions of the scenario, such as data size and
complexity.
Readability
Subqueries have an advantage in readability. Well-constructed
and properly formatted subqueries are often much easier to read
and understand than JOINs, making it simpler to trace the
logical steps of query execution. In contrast, JOINs can appear
more complicated, especially when they involve numerous
conditions.
Flexibility
Subqueries are more flexible and adaptable to different
requirements compared to JOINs. Additionally, they can be
utilized in scenarios where JOINs are not allowed. JOINs, on the
other hand, may impose limitations based on specific
circumstances.
Ultimately, the choice between using a subquery or a JOIN in
your SQL query will always depend on the specific situation at
hand and all the conditions and requirements for each particular
scenario.
Common mistakes and how to avoid them
When composing complex queries with subqueries, it's easy to
make mistakes that can cause the query to malfunction. To
address typical mistakes in subqueries, we can categorize them
into general mistakes and specific mistakes related to the
specificity of subqueries.
Incorrect column name in a subquery
One of the most frequent errors when writing queries is defining
the wrong column in a subquery, mistakenly substituting it with
a similarly named column from the main query. The main issue
here is that such a query might not throw an error immediately,
making it difficult to detect. However, the solution to this
problem is relatively simple. Using table aliases in subqueries
is the best approach. The system would promptly throw an error
about the invalid column name and point you to the core of the
problem.
Ambiguous columns
Another common cause of errors is when a column name appears in
several tables involved in a subquery. This ambiguity may lead
to incorrect results or failures as the database engine might
refer to the wrong table. To overcome this, the solution is
similar to the one mentioned above — use unique names for
all columns in all tables or qualify column names with aliases.
By doing this, you ensure that your query will always reference
the right target table and column.
Syntax errors
Missing parentheses, spelling errors in column names, incorrect
operators, and other issues can lead to incorrect query
performance and errors. To avoid syntax errors, a deep
understanding of SQL rules is essential, along with the use of
specialized tools. These tools help you write code faster,
validate syntax on-the-fly, debug code, format it for better
readability, and provide other options to ensure high-quality
code production.
In conclusion, a unified recommendation to avoid errors or at
least minimize their impact on your work is to always test your
queries before running them against the actual database and make
regular database backups.
Tools for simplifying the construction of SQL subqueries
Constructing complex SQL queries, including those with nested
subqueries, can be a challenging task for SQL experts. While
coding assistance tools can be helpful, there's an alternative
approach of using a visual format that has proven to be more
beneficial in many cases.
The dbForge product line for SQL Server and its flagship
product,
dbForge Studio for SQL Server, provides the functionality for both scenarios. It has a powerful
SQL Coding Assistance
module offering plenty of features to accelerate code writing
and improve the quality of the output, and it also offers the
possibility to construct SQL queries visually with the
Query Builder tool.
The Query Builder in dbForge Studio for SQL Server simplifies
the creation of SQL queries, no matter how sophisticated they
may be, by transferring the process into a user-friendly visual
UI with drag-and-drop functionality for ready-made blocks. As a
result, manual coding is no longer necessary.
When it comes to constructing SQL queries with subqueries, the
Query Builder offers the following essential functionality:
-
Graphical SQL query building with undo and redo options for
easy revisions
-
Query outlining in a Document Outline window for better
organization
-
Visual addition of subqueries to any part of the main query
for seamless integration
-
Visual editing of subqueries, enabling quick modifications and
adjustments
- Converting the visually designed query into SQL code
If you want to explore how to design the SELECT query with Query
Builder for SQL Server, feel free to
watch this video.
By utilizing the dbForge Query Builder for SQL Server, SQL
experts can significantly streamline their query construction
process, enhance productivity, and reduce the complexity
associated with nested subqueries.
Conclusion
SQL subqueries are fundamental concepts and a powerful and
essential tool in the database developer's toolkit. Their
importance lies in their ability to enhance query readability,
simplify code maintenance, and optimize database performance.
Mastering this feature will undoubtedly lead to more streamlined
and effective database operations and the overall success of
data-driven applications and systems.